

 Réagir
Réagir  Imprimer
Imprimer  Envoyer
Envoyer  S'abonner
S'abonner 
Le référencement naturel est un travail indispensable à fournir si l’on souhaite que son entreprise soit visible par les internautes. Pour être efficient, il vous faudra collecter un maximum de données, non seulement sur les performances de votre site internet mais également sur les habitudes de vos clients. Une analyse et un traitement régulier des données est primordial afin d’établir une stratégie efficace et de l’adapter en fonction des résultats obtenus.
Les bonnes pratiques SEO
Les bases indispensables à connaître
Le référencement naturel est quelque chose qu’il faut comprendre et maîtriser pour prétendre être visible sur Internet. Qui dit référencement naturel dit moteur de recherche, et en France, Google a le monopole (plus de 90%). Google a mis en place plus de 200 critères à respecter pour qu’un site internet soit bien référencé. Certains facteurs favorisent donc ce référencement, et d’autres le bloquent. Afin de simplifier la compréhension sans avoir à énumérer les 200 critères de Google, il est possible de schématiser le fonctionnement du référencement naturel en pyramide. En effet, cette “pyramide du référencement” fait apparaître l’ensemble des composants qui doivent être optimisés pour obtenir une bonne visibilité :
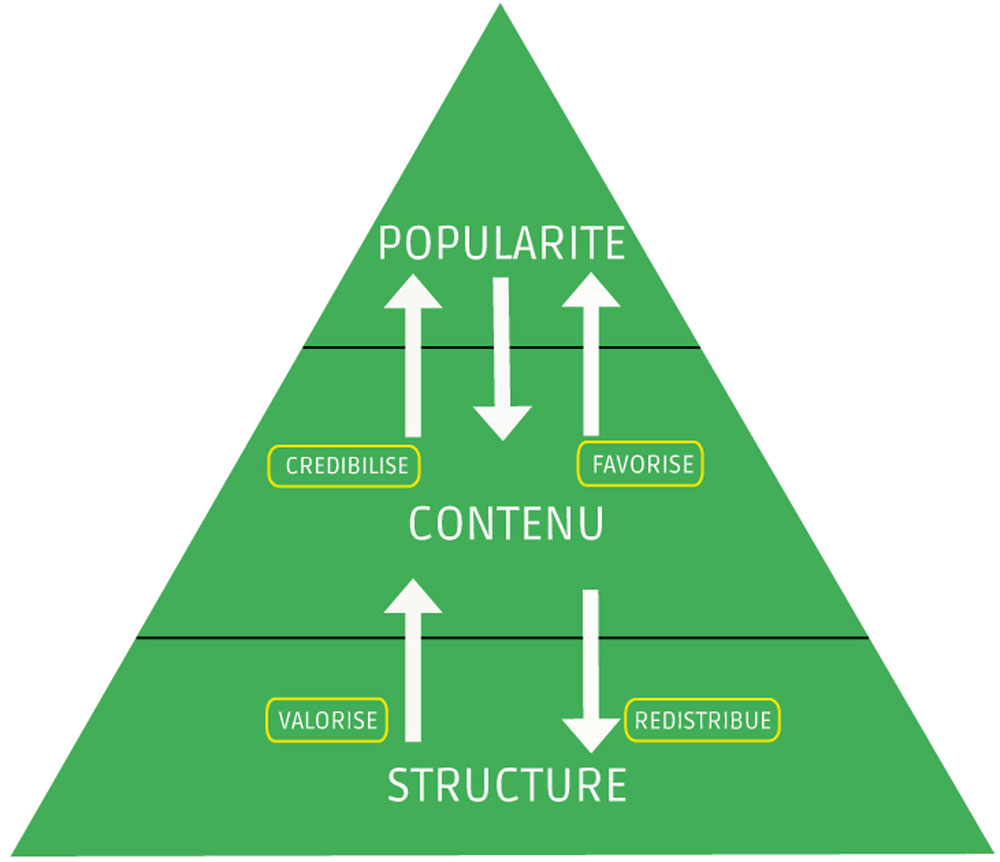
Ce qu’il faut retenir:
La popularité représentant tout simplement ce que le Web dit de votre site Internet via les liens (réseaux sociaux, communiqués de presse, soumissions aux annuaires, réseaux spécifiques).
Le contenu représente essentiellement le contenu textuel du site :
- La formation des rédacteurs
- La recherche des mots clés
- Les micro contenus
- L’optimisation des textes
- Les intitulés des liens
- Le balisage sémantique
- Les titres, les méta, les balises, les ancres de lien
- Le maillage interne
- La duplication du contenu (qualité rédactionnelle)
- L’architecture de l’information
Et enfin la structure, c’est le code que contient le site et le met en forme :
- Les noms de domaine
- L’accessibilité technique
- La qualité du code
- Respect des normes HTML5, W3C, site https, limiter le JavaScript
- Temps de réponse court
Il ne faut pas forcément se focaliser sur les requêtes ou mots-clés stars pour être bien référencé et visible sur internet. Si vous vendez un objet très spécifique, tel qu’un téléviseur LED de 121 cm, il est inutile de se focaliser sur le mot clé “télévision”, ou encore “téléviseur”. L’internaute qui recherche votre produit et qui est prêt à l’acheter, se donnera plus de mal pour le trouver rapidement en précisant le plus possible sa requête.
Non seulement Google a le monopole en tant que moteur de recherche, mais il fait également en sorte que l’internaute n’ait même plus à cliquer sur un site internet après avoir effectué sa requête.
La preuve en image :
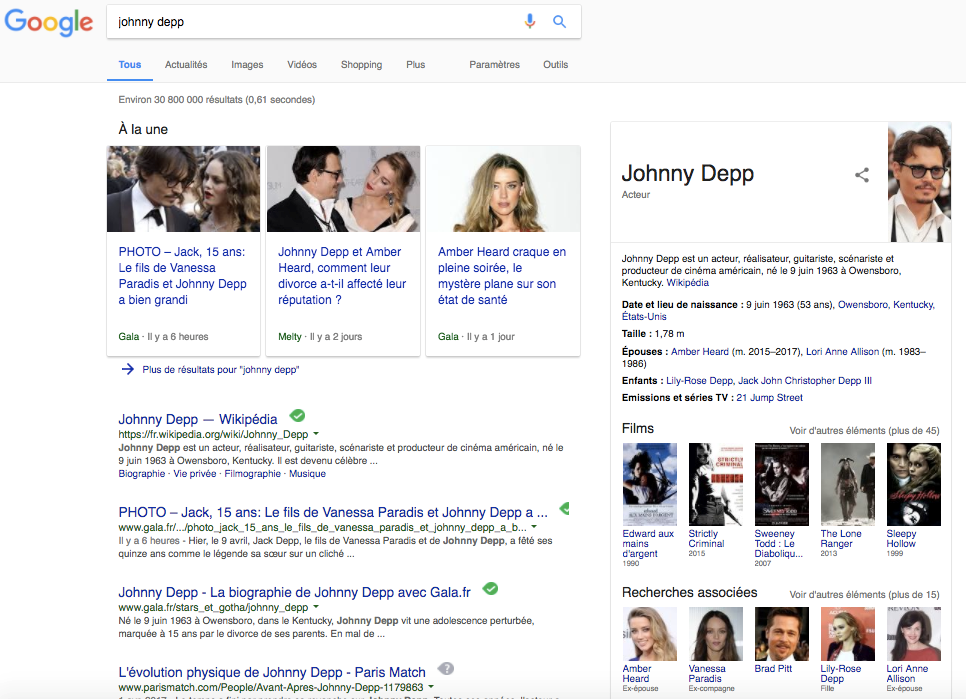
L’internaute a seulement tapé “Johnny Depp”, sans plus de précisions, et pourtant déjà Google fait en sorte que ce dernier connaisse tous les détails de la vie de Johnny Depp. Il est donc possible de connaître jusqu’à sa taille, ou même le prénom de sa dernière ex-petite amie en date, sans que vous n’ayez à charger une autre page. Référencer son site internet passe donc par le respect de toutes les règles imposées par Google, et même si celles-ci sont appliquées avec le plus grand des soin, nous venons de voir que Google use d’autres ruses afin de retenir les internautes sur sa page.
Mais alors est-il possible que Google indexe un site internet qu’il ne connait pas ? Ou mieux encore, est il possible de référencer un mot qui n’existe pas ? Il est intéressant de se pencher sur le fonctionnement des bots (robots que Google utilise afin d’évaluer la pertinence d’un site). La question se pose alors : l’homme peut-il toujours tromper un robot, si puissant soit-il ?
Les secrets de l’indexation
Comme nous l’avons vu précédemment, un site web subit une évaluation et doit donc respecter les critères cités ci-dessus afin d’être considéré comme pertinent. Or, il existe pas moins de 2 milliards de sites internet. Vous vous doutez bien que ce travail d’analyse est humainement impossible. Google a donc conçu un robot appelé Google bot. En réalité, ce n’est pas un mais des milliers de Google bots qui effectuent régulièrement ces contrôles.
Le fonctionnement d’un bot
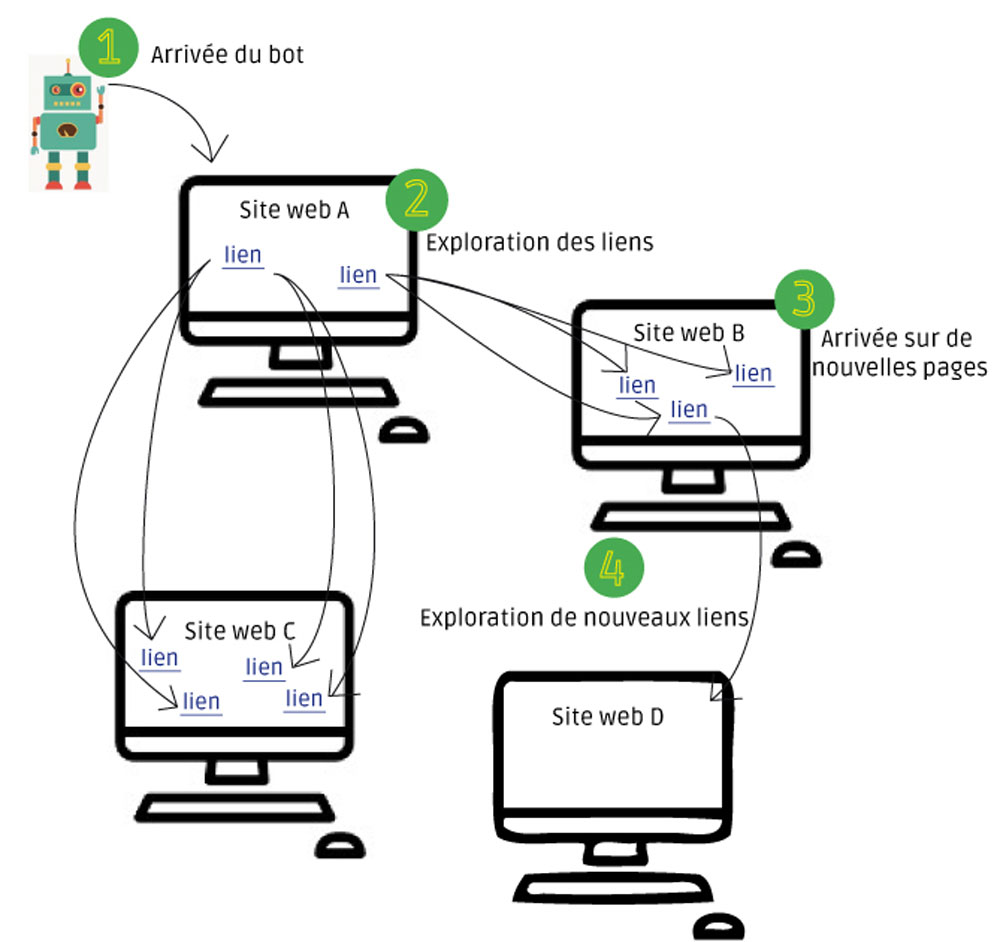
Un bot est un programme informatique qui parcourt les pages d’un site web (on utilise également le terme crawler) et décide si ces dernières sont assez pertinentes pour être indexées (stocker dans le serveur de Google). Voici comment il procède :
1. Arrivée du bot sur un site
Le robot analyse le code source html de votre page web. Il l’enregistre et la fait parvenir aux serveurs de Google.
2. Exploration des liens
Il va ensuite repérer les liens codés en dur dans le code html soit ceux inscrits dans la balise <a></a> et les suivre.
3. Arrivée sur de nouvelles pages
Puis, il va analyser les codes sources des pages sur lesquelles il va atterrir.
4. Exploration de nouveaux liens
Sur ces nouvelles pages, il va repérer les liens et les suivre. Et ainsi de suite, le cycle recommence.
On peut connaître la fréquence de passage des Google bots même si cette dernière varie selon les sites internet (ancienneté, pertinence du contenu, fraîcheur…). Grâce à Google Search Console, vous aurez une vision globale de l’activité des robots durant les 90 derniers jours avec notamment les pages explorées, les kilo-octets téléchargés par jour ainsi que le temps de téléchargement d’une page. Si vous souhaitez obtenir des informations plus détaillées (heure de passage…), il vous faudra contacter directement votre hébergeur et demander à visualiser les logs du serveur. La data est donc au cœur de toute la stratégie.
Notez que les pages d’un site qui sont mises à jour régulièrement sont plus visitées. C’est pour cette raison que les pages dites statiques sont en général moins bien référencées. Pour les sites web d’actualités comme les sites de presse, un bot peut crawler les pages plusieurs fois par jour.
Le contenu roi
Même si les algorithmes des robots Google ont été conçu par des hommes, cela reste de “simples” formules mathématiques. Les Google bots n’ont donc pas la vision qu’un homme pourrait avoir. En effet, si l’oeil humain distingue parfaitement les divers éléments de la mise en forme d’un site internet à savoir le menu, les images, le texte…ce n’est pas le cas des robots. Ces derniers ne voient que le code source HTML autrement dit le contenu.
Le contenu d’un site internet est donc l’un des éléments indispensables à travailler pour améliorer son référencement. Il doit :
- être pertinent (en fonction du ou des mots-clés choisis)
- posséder un champ lexical cohérent
- unique (attention au contenu dupliqué qui est pénalisé par les moteurs)
Les Google bots sont capables d’évaluer ces critères. Cependant, ils peuvent être dupés. Nous en avons fait l’expérience dans le cadre d’un concours de référencement.
Le principe : Créer un blog sur un thème libre et ressortir dans les moteurs de recherche sur un mot-clé imposé et inventé : Digmasins (les 3 premières lettres de Digital Master Inseec)
Contexte : Concours effectué au sein de l’Inseec Bordeaux entre les élèves de Master 2 spécialisé en Marketing Digital.
Ce concours est bien la preuve que l’on peut réussir l’indexation et le référencement d’un site internet sur n’importe quel mot-clé du moment que le contenu possède les bons critères.
Pour voir tous les résultats, rendez-vous sur Google.
Alors, inspiré(e) ?
Source :
- « Réussir son référencement web » – Oliver Andrieu
- Eric Garletti – Agence Atypicom (image pyramide)
- Définitions-marketing.com (image bot)





 DATA
DATA
Merci pour ces petites illustrations très pratiques et détaillées sur le SEO bien vu comme sujet!
Des bases cruciales pour optimiser le référencement. Bien vu!